MySQL底层架构
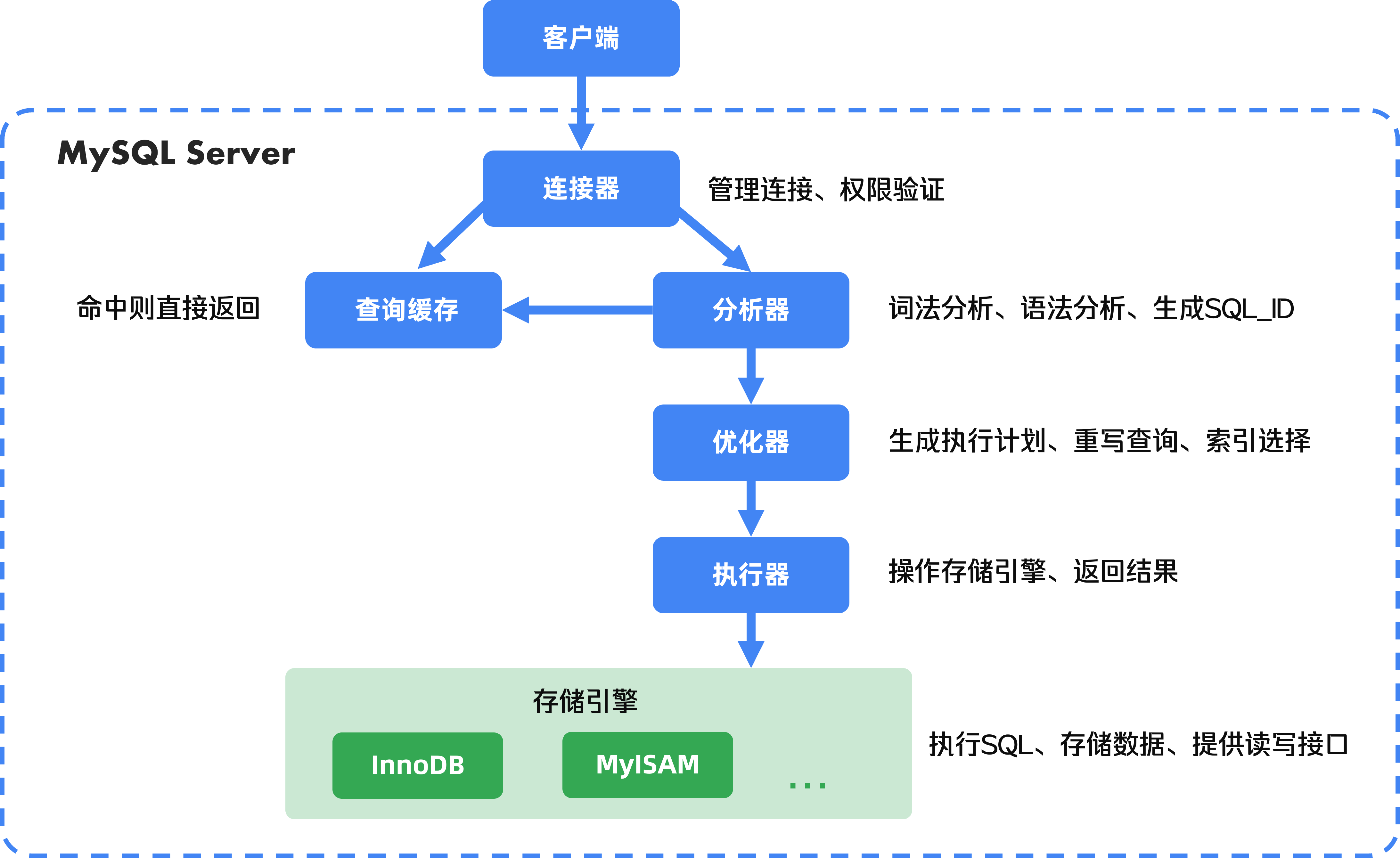
MySQL包含一个Server层和一个存储逻辑层,大部分核心功能和内置函数、所有跨存储引擎的功能都在Server层实现。
存储引擎层负责数据存储和提取,支持InnoDB、MylSAM、Memory等多种存储引擎,目前默认用的是InnoDB,除非在创建表的时候通过engine=xxx来手动选择。后面如果没做特殊说明,都指的是InnoDB引擎。
查询SQL的执行过程
1. 连接器
我们都知道,在启动mysql server后,通过如下的mysql的连接命令进行连接:
mysql -h ip -P port -u user -p
首先会和连接器打交道,连接器负责鉴权和建立连接。
和MySQL建立连接的方式是TCP/IP或者socket(取决于是连接远程服务器的MySQL还是本地的)
建立连接后,MySQL会检查权限表,查看该用户有没有权限连接到MySQL实例。验证通过之后会将用户的权限信息缓存起来,之后都基于缓存中的权限信息来执行sql。
连接后如果超过wait_timeout(默认是8小时)一直都没有操作,就会自动断开。下一次就要重连。
MySQL 服务支持的最大连接数由max_connections 参数控制,超过这个值,连接器就会拒绝接下来的连接请求
2. 查询缓存
把之前查询过的语句和结果通过k-v对的形式缓存在内存中,如果之后某次的查询在缓存中找到了,就直接返回。 不过实际上这个功能并不好,只要表被更新了就会失效,而且还占缓存,除非是经常不更新的表,所以MySQL8.0直接删除了查询缓存。
3. 分析器
MySQL需要解析这条语句,先做词法分析,再做语法分析,从而理解这条语句的需求。属于编译原理的内容,这里就不细说。
如果遇到一些语法问题,就会在这里返回报错。
4. 预处理器
在分析好了SQL语句后,MySQL就了解了具体的需求,但是在实际执行之前还需要进入优化器进行优化。
在预处理阶段,首先检查SQL查询的表和字段是否存在,如果有*,就将*替换为所有的字段。
5. 优化器
优化器主要负责将 SQL 查询语句的执行方案确定下来,比如在表里面有多个索引的时候,优化器会基于查询成本的考虑,来决定选择使用哪个索引。或者比较复杂的查询语句,有多种查询的嵌套方式,优化器的作用就是选择一种最佳方案来执行,从而提高效率
6. 执行器
首先判断用户是否有权限使用这张表。最前面的连接器鉴权是判断是够能够连接MySQL实体,而这里是精确到表的权限。
然后根据对应表的引擎定义,使用存储引擎的接口执行查询,执行器是与存储引擎对接的。
列举以下三种场景,看执行器与存储引擎如何交互。
- 主键索引查询
如果是主键索引查询,比如:
|
|
- 执行器首先调用 read_first_record 函数指针指向的函数,然后InnoDB定位符合条件的第一条记录
- 如果存在就会将记录返回给执行器,不存在就会报错
- 执行器拿到记录后判断记录是否符合所有查询条件,进行筛选
- 查询是while循环,下一次会指向一个永远返回-1的函数,跳出循环
- 全表扫描
没有索引,优化器选择ALL的方式
|
|
- 执行器调用read_first_record 函数指针指向的函数,因为是all,这个函数会指向InnoDB全扫描接口。
- 执行器会判断这条记录的name是不是"engine",如果是的话就会一条条发送给客户端。(实际一下全部返回是因为客户端会等待查询完成才会显示所有记录)
- 查询是while循环,下一次调用read_record指向的还是全扫描接口,存储引擎会扫描下一条记录。
- 不断重复,直到读取完
- 索引下推
索引下推可以将server层负责的索引条件筛选操作下放到存储引擎。
比如建立了(a, b)联合索引
|
|
联合索引遇到范围查询,之后的会停止匹配,索引到a为止,b用不到联合索引。
如果不使用索引下推:
- server层定位到满足a>20的第一条记录(因为有索引)
- 存储引擎将这条记录进行回表,查询完整的记录返回给server层
- server层再判断是否b=10,c=1,然后依次遍历...
如果使用索引下推,判断b的过程就给了存储引擎
- server层定位到满足a>20的第一条记录(因为有索引)
- 存储引擎不回表,而是先判断b=10是否成立,如果不成立就直接跳过,成立才回表
- server层拿到数据后再判断其他的查询条件,比如这里是判断c=1。之后依次遍历。。
所以可以看到,索引下推可以减少很多回表操作,提高查询效率。
执行器会维护一个结果集,在查询的过程中如果查询到了符合要求的记录,就会追加进结果表,最后将这个结果表返回给用户。至此就完成了一条SQL查询语句的执行。
InnoDB引擎架构简述
MySQL默认的存储引擎是InnoDB,其架构图如下:
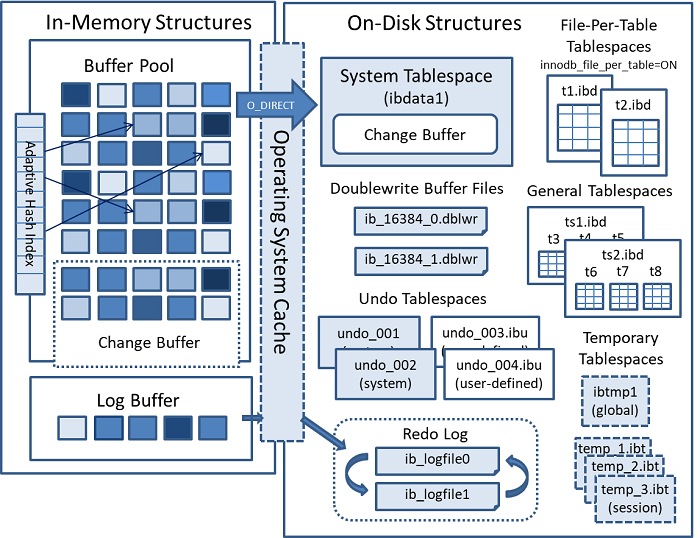
因为确实非常复杂,也不是专门研究数据库,所以不会讲解非常详细,只是简单的提一下InnoDB的架构。
主要包括内存池、后台线程和存储文件。
内存池包括:磁盘缓存、redo log缓存等 后台线程包括Master Thread、IO Thread和Pruge Thread 存储文件包括:表结构文件.frm、共享表空间文件ibdata1、独占表空间文件ibd、日志文件redo文件等
缓冲池
Buffer Pool(缓冲池)是主内存的一块区域,由于直接从磁盘读取数据会造成性能瓶颈,InnoDB在访问数据的时候,会将数据页缓存到缓冲池中,从而加快速度。缓冲池的目的就是为了提高数据库的读写性能。
缓冲池会把数据页链接为链表,通过LRU或者其他缓存代替算法来替换掉老的缓存。
对于修改数据的情况,也会先修改缓冲池的数据,然后通过Master Thread刷到磁盘上。
redo log也会先放入缓冲区,然后刷到redo log文件中。
后台线程
Master Thread负责将缓冲池的数据异步刷新到磁盘中,IO Thread负责IO,Purge Thread用户回收已经提交的undo log。
存储文件
逻辑存储结构从打到小依次是表空间(TableSpace)、段(Segment)、区(Extent)、页(Page)、行(Row)
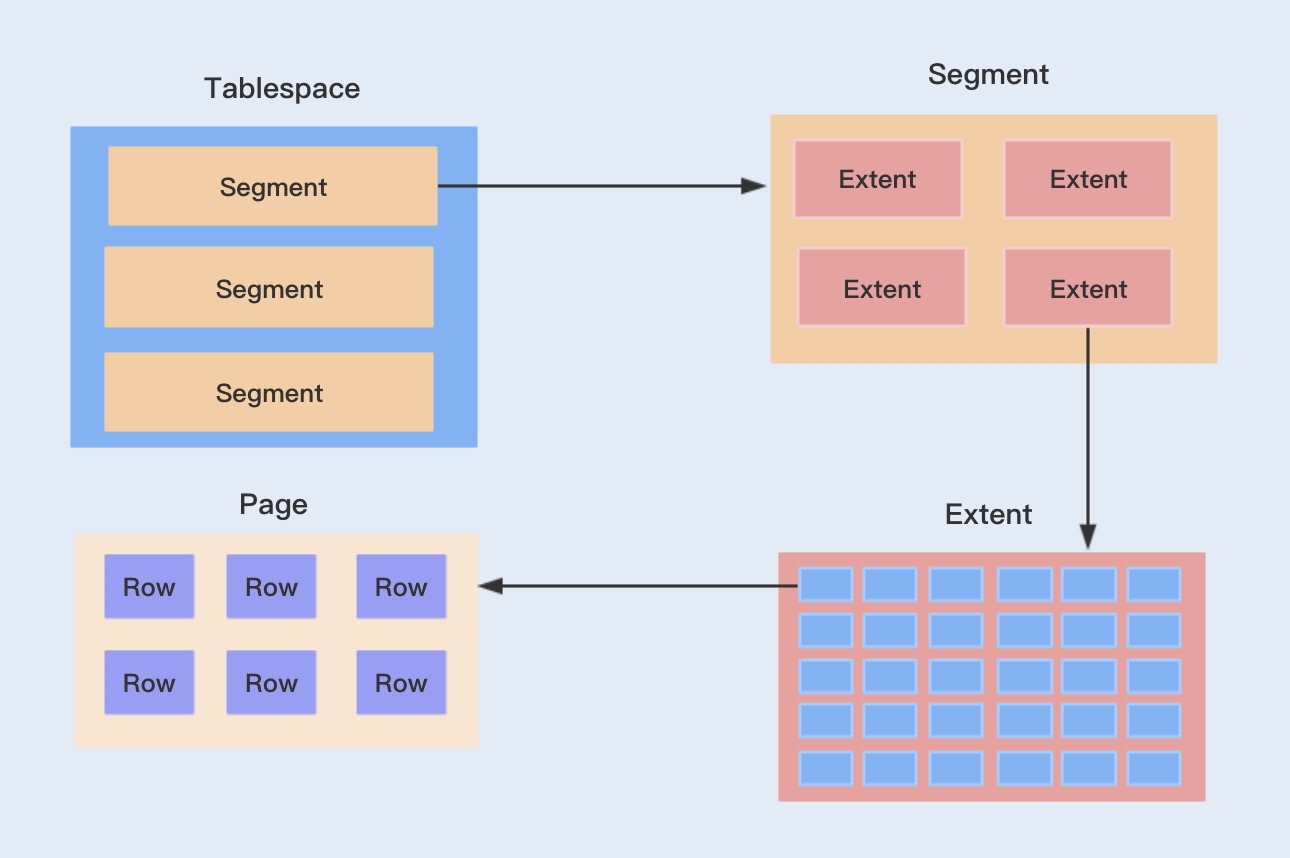
表空间分为共享表空间(ibdata1)和独占表空间,默认会全部放在共享表空间中,也可以设置innodb_file_per_table = 1来开启独立表空间模式,这一模式下所有的表都有自己的独立空间。
表空间由段组成,段分为数据段、索引段、回滚段等,InnoDB采用B+树作为索引的底层数据结构,B+树的非叶子结点就是索引段,叶子节点就是数据段。
区是表空间的单元结构,每个区的大小是1Mb
页是组成区的最小单元,也是InnoDB磁盘管理的最小大单元,每个页为16Kb
数据按行进行存放,每个页最多允许存放7992行