ACID、BASE、2PC/3PC
ACID
在讲ACID之前,先讲本地事务,事务最早在数据库等课程中就接触过,简单来说,事务提供一种“要么什么也不做,要么全做完”的机制。
ACID特性是数据库事务的基本特征,包括:
- Atomicity 原子性
- Consistency 一致性
- Isolation 隔离性
- Durability 持久性
合称就是ACID(在英语中正好是酸的意思,之后的BASE碱也与之对应)
然而分布式事务和本地事务不同,假设有一个操作需要多个机器上执行,要么都执行,要么都不执行。 要保持分布式事务的ACID,方法有二阶段提交协议和TCC。
2PC二阶段提交协议
一个事务跨越多个节点,成为分布式事务,为了保持ACID,需要引入一个协调者的角色来统一掌控所有节点的结果。
整个过程被分为两个阶段:
- 准备阶段(投票)
协调者给每个参与者发送Prepare信息,每个参与者有两种选择: ①返回失败 ②本地执行事务返回成功,但不提交。询问之后的所有事务操作都记log,以便之后的恢复。
- 提交阶段(执行)
如果协调者收到了失败或者超时,就直接给每个参与者发送回滚消息,否则就发送提交(commit)消息。 参与者如果收到提交消息,就提交事务,并释放资源和锁。如果收到回滚消息,就回滚事务,并释放资源和锁。
二阶段提交协议的缺点:
- 同步阻塞,从投票开始到提交完成的这段时间,所用的资源被锁死
- 单点故障,如果协调者故障了,就会一直阻塞
- 数据不一致,第二阶段发送commit时可能部分节点因为故障收不到,导致只有一部分执行了commit。 等
之后有提出三阶段协议3PC,对二阶段协议进行了改进,然而由于增加了通信成本,实际用的并不多,就不细讲。
TCC(Try-Confirm-Cancel)
TCC是一个业务层面的协议,需要在业务代码中编写,包含了预留、确认或撤销三个阶段。 核心思想是针对每个操作都要注册一个对其对应的确认操作和补偿操作。 首先是try阶段,先通知各个节点的将要进行的操作。 如果try阶段的回复都是ok,就执行确认操作,通知各个节点要执行操作;如果try阶段有错误或者超时,就执行撤销操作,
可以说ACID是CAP一致性的边界,也就是最强的一致性。
BASE
BASE则是追求可用性,是CAP中AP的拓展。
BASE的核心是基本可用(Basically Available)和最终一致性(Eventually Consistent)
比如遇到峰值,可以用四板斧解决:
- 流量削峰,将访问请求错开,比如多个秒杀商品放在不同的时间开始
- 延迟请求,比如买火车票抢票的时候等一段时间系统才处理
- 体验降级,比如先用小图片代替原始图片
- 过载保护,请求放入队列中排队处理,超时了就直接拒绝,队列满了之后就清除一定的请求。
目的是在基本可用性上保持妥协,谁也不想牺牲这些服务,但是为了可用性必须这样。
最终一致性是指所有数据副本在经过一段时间的同步之后,最终能保持一致性。 显示生活中,除了金融等对一致性要求极高的领域,它们会使用强一致性。绝大部分互联网系统都采用最终一致性。
实现最终一致性的方式用的多的有以下几种:
- 读时修复,查询数据的时候如果检测到不同的数据,系统自动修复
- 写时修复,写失败的时候先将数据缓存下来,之后定时重传
- 异步修复,最常用,通过定时对账来检测副本数据的一致性并修复
然而异步修复和读时修复的开销比较大,需要进行一致性对比,而写时修复的开销低。
如果要设计分布式数据库的一致性的时候,可以采用自定义写一致级别(All、Quorum、One、All)来让用户自主选择业务所适合的一致性级别
BASE通过牺牲强一致性来获得高可用性。
CAP
分布式系统的最大难点之一就是维护各个节点之间的数据状态一致性。 需要通过数据库或者分布式缓存来维护数据的一致性。
CAP是三个缩写的组合:
- C(Consistency):数据一致性,分布式系统中,同一份数据可能存在于多个实例中,其中一份的修改必须同步到所有它的备份中。也就是说每一次必然能读到最新写入的数据,或者返回错误。
- A(Availability):服务可用性,服务在接收到客户端请求时必须要给出响应。在高并发和部分结点宕机的情况下依然可以响应。也就是每一次必然会返回结果,但是不保证是最新的正确的。
- P(Partition tolerance):分区容忍性,由于网络的不可靠性,位于不同网络分区的结点可能会通信失败,如果能容忍这种情况,那么就满足分区容忍性。也就是说出现问题能够容忍。
一个分布式系统不可能同时满足这三个基本需求,最多只能满足两项。
- 满足CA
也就是必然一致而且能够返回正确结果,这样是不存在的,其实就是单Server,不叫分布式系统。
- 满足CP
牺牲A,只要系统中有一个Server没更新完,就返回错误,否则就返回正确的最新的值。
- 满足AP
牺牲C,也就是只要Server接收到请求就返回目前的值,但是不能保证一定是最新的正确的值。
分布式系统必须满足分区容忍性,也就是只能从A和P中进行取舍,数据一致性和服务可用性只能满足一个。当然实际情况不可能只顾一个而完全放弃另一个,而是在主要关心一个的前提下尽量满足另一个。
比较成熟的服务注册与发现有以下几个:Consul、Etcd、Zookeeper、Eureka
其中Consul、Etcd、Zookeeper满足了CP,而Eureka满足了AP。
一致化模型Consistency Model
对Consistency的不同程度的要求也衍生出了多种不同的等级模型。根据不同的情况采取不同的模型。
假设有一场球赛,记分员负责将分数写入主Server,然后会将操作复制到各个replica server,读取分数的话可能是任意一个server。
k=0,1分别代表主队和客队,如果主队得了一分,记分员操作是:
v = get(k)set(k, v+1)
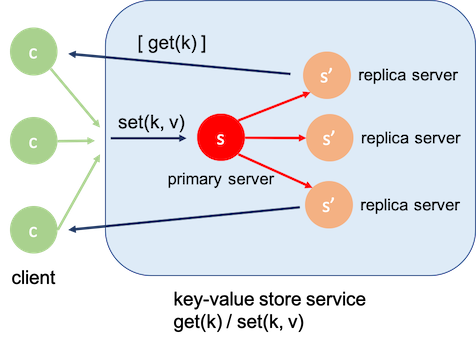
假设目前比分是2:5
Strong Consistency
对于任何一个人,读到的一定是最新的
Eventual Consistency
只把结果给其他Server,只能保证最后的时刻会更新到正确的最终值,但是之前读到任何小于结果的得分都有可能,甚至是完全没出现过的得分,比如2:0
Consistent Prefix
连同操作一起给其他Server,从而保证读到的一定是比赛中的某个比分,历史发生过。
Bounded Staleness
保证读到的一定是t以内的结果。Bounded=0则为Strong Consistency。Bounded=无穷则为Eventual Consistency。
Monotonic Reads
可能返回任何结果,但是接下来会持续从同一个replica server中读取,保证每一次都至少会比之前的值新。
Read My Writes
如果某个client对Server进行了set操作,那么之后的get必然是set的值。
不同的角色,要求的系统模型不一样。 记分员:只有他会写入系统,用Read My Writes 裁判:只能Strong Consistency 报分员:保证是历史正确比分,然后每一次至少比上次新,Consistent Prefix+Monotonic Reads 记者:Bounded Staleness就可以,多等点时间 观众:无所谓,Eventual Consistency都行
银行的系统必然是Strong Consistency,只能最新。而DNS只要是Eventual Consistency就可以,因为需要快速返回结果,不是最新的也可以接受。
Quorum System
Quorum System随着Amazon与2007年发表的Dynamo: Amazon’s Highly Available Key-value Store论文而提出,这篇论文是NoSQL的代表之作。DynamoDB是一个NoSQL数据库,支持键值和文档数据结构,具有Strongly Consistent和Eventually Consistent。
之前都是往一个Leader Server里写入,然后复制到replica server里,而我们更需要的是写入的时候任何一个Server都可以,读取的时候也是任何一个Server都可以。 也就是Leaderless Replication
但是这样做的问题在于,如果两个写入操作的时间比较靠近,很可能出现对于不同的服务器而言,指令到达的时刻顺序不一致,从而错误。
一种方法是每次写入都加锁,也就是去抢每个replicas server的锁,直到都写完了才释放所有的锁,让下一个写入进入。但是这样的话过于严格,效率低下。
把条件放松一些。 对于写入操作,当一个client取得w个replicas的Lock才被允许写入。 取得R个replicas的Lock才被允许读。 写入时搭配timestamp。
只要W+W>N就可以防止同时写的发生,保证不会出现最新的值不明确的情况。这个不解释。
只要W+R>N就可以防止同时读写的发生,保证不会出现读取的值不是最新值的情况。配合timestamp之后,根据抽屉理论,读的时候至少会读到一台最新的server,从而根据timestamp可以找出它。
通过Quorum System,可以不必设置primary server、replica server的形式,直接对任一server进行读写,仍然能保证Strong Consistency。
这样的话,通过使用DynamoDB,Amazon会在世界各个地方的数据中心存放你的数据,进行备份,也能通过local replica进行加速。
Read-Repair和Anti-Entropy
如果说有几个节点瘫痪了,导致每个都无法拿到超过一半的锁。
Read-Repair就是在读取的时候不仅通过timestamp拿到最新的结果,还顺便将最新的结果写回其他的server里去。这种适用于频繁读取的情况。
另一个方法是Anti-Entropy,也就是单独创建一个process,通过检查replica的版本并将所有server都同步成最新的。适用于读取不频繁的情况。
Hinted Handoff
故障的server恢复之后,系统会写回这个server,这种做法叫Hinted Handoff。 写失败的请求会缓存到本地硬盘上,并周期性的尝试重传。
Quorum NWR
对于AP系统,可以保证最终一致性但是无法保证强一致性。如果想满足强一致性,可以借助Quorum NWR。
Quorum NWR可以根据业务的特点,调整一致性级别。
三个要素:N、W、R
N:复制因子,也就是一个集群中,数据有多少个副本,当然不同的数据可能有不同的副本数 W:写一致性级别,成功完成W个副本更新,才完成写操作 R:读一致性级别,读一个数据对象需要读R个副本
W + R > N:不会出现并行读写,一定能读到最新值 W + W > N:不会出现并行写 W + W <= N:可能出现不一致 W + R <= N:可能会读不到最新的值 R + R > N:
分布式系统的时间
通常会采用W+W<=N来尽量保证Availablity,这种情况下如何规避并行写导致的不一致呢。
一个方式就是要了解两个指令在发出时的先后顺序,而不是到达时的顺序,从而保证一致性。看起来通过发出信号时就附加timestamp可以解决问题,看起来每台机器的时间是一样的,然而实际上并不一定。
由于每台机器自身的时间并不一定准确,甚至可能会出现接受到信息的timestamp比机器当前时间还要晚的情况(收到来自“未来”的消息),这样就很离谱,明显不合理。
Lamport Logical Clock
在消息里夹带一个timestamp,但是在传递的时候,每个结点接受到timestamp后,会比较自身时间与timestamp的大小,然后选择最大的那个置为新的timestamp,从而保证一定递增。收到的消息的timestamp比本身时间还大的话,就将自己的时间改为timestamp的时间。
- 每个参与者最开始都保存一个timestamp=0
- 如果在本地发生,timestamp+1
- 如果传递这个消息,timestamp+1,然后传递时附带该timestamp
- 如果接受这个消息,timestamp = Max(本地Clock, 消息timestamp) + 1
(Lamport发明了Latex)
Vector Clock
Lamport timestamp会显示两个先后的事件有因果关系,但是实际逻辑上并不一定,可能只是同时平行发生。
对于N个Node的系统,Vector Clock让每个Node都存储一个长度为N的timestamp vector
对于$Node_i$而言,存储$Vector_i = {t_0, t_1, ..., t_n}$
- 初始化每个Node的vector中的每个元素都为0
- $Node_i$发生一个事件,$V_i[t_i]+1$
- $Node_i$发生一个发送事件,$V_i[t_i]+1$,并夹带这个vector
- $Node_j$发生一个接受事件,$V_j[t_i] = V_i[t_i]$、$V_j[t_j] = Max(V_j[t_j],V_i[t_i]) + 1$
参考:https://ithelp.ithome.com.tw/users/20121042/ironman/2792