介绍
MapReduce是一个用于处理和生成大型数据集的编程模型和相关实现,它是一个分布式模型,通过一个Map函数将k/v对生存一组中间态的k/v对,然后通过一个reduce函数将所有的中间态k/v对进行聚合。 MapReduce运行在一个大型的商用机器集群上,比如可以在数千台机器上处理大量TB级别的数据。 实际上Google早已将其用于实际的任务,每天有超过1000个MapReduce任务在谷歌的集群上运行。
面对百亿级别的爬虫数据、日志文件等,常规方法不可能做到时效性,只能采用分布式系统进行并行计算。
编程模型
输入是一系列k/v对的set,输出也是一系列k/v对的set
用户需要编写Map和Reduce这两个函数,其中Map函数通过输入pair来产生中间过程的k/v对 接下来会将Key为I的中间值传递给对应处理Key I的Reduce函数 Reduce函数接受一系列的Key为I的值,然后merge在一起,每次只有0或1 具体的见下面的例子。
例子
输入文件首先分块, 需要一个Map函数,每个输入文件输入Map进行处理,每个都是并行的,产生对应的输出,输出是一个list形式的Key/Value的键值对。
假设我们的功能是读取字符出现的次数。 假设输入为"abbac",被拆成了三个文件,总共也就这三个Key。分别是"ab","b","ac",并行输入进Map,三个输出分别为: (a,1), (b,1) (b,1) (a,1), (c,1)
然后进行reduce操作,对于每个Key,会传入reduce函数进行汇总,去统计每个Key的出现个数。这也是并行的。
那么经过reduce操作之后,输出为: (a, 2) (b, 2) (c, 1)
完整的Job由一系列的MapTask和一系列的reduceTask组成。
下面来说说对于统计字母的功能下,Map和Reduce这两个函数的结构:
|
|
|
|
MapReduc和GFS都运行在一起,在并行进Map的时候,实际上避免了网络传输,中控通过某些方式能够知道该文件存在哪台主机里,然后在该主机调用Map本地操作,从而减少带宽传输限制。后面reduce只能通过网络。
最开始是按行存储,然后按列存储,这个过程叫Shuffle,从Map服务器到Reduce服务器,这一过程很消耗网络。
类型
map函数 输入是(k1, v1),输出是list(k2, v2)
reduce函数 输入是(k2, list(v2)),输出是list(v2)
以统计词频为例,这里map的输入是(filename, fileContent),输出是对于每一个单词为key的k/v列表,比如["Apple": 1, "Banana": 1,...]。
这里reduce的输入就是一个单独单词的一系列值,比如"Apple", [1, 1, 1,...],然后输出是该单词的词频。
更多的例子
除此之外还有很多适用于MapReduce的很好的例子。
实现
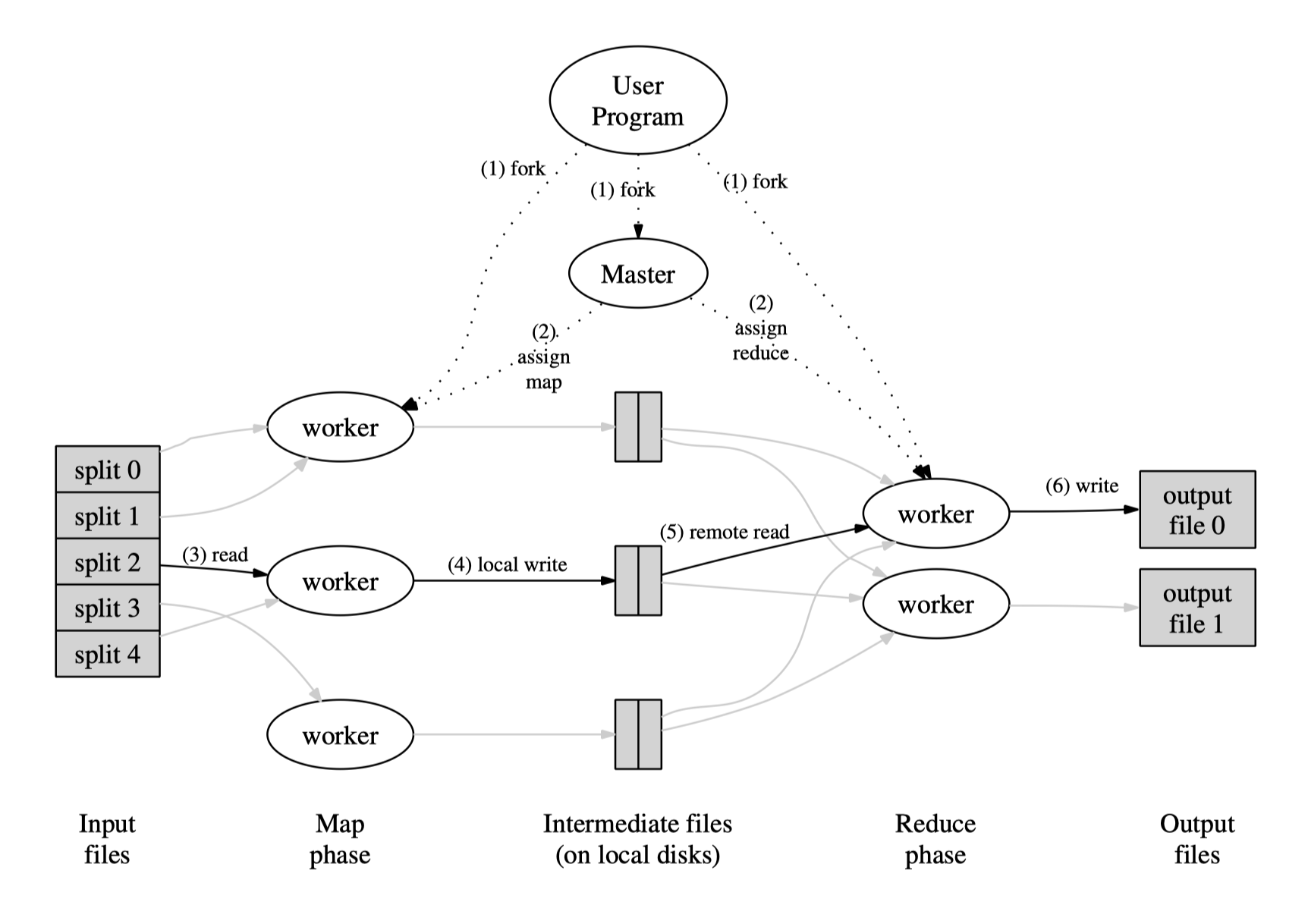
分割输入数据,分成M个子集,被调用分布到多台机器上并行处理。之后分割中间key形成R个片(比如通过hash(key) mod R),reduce调用分布到各个机器上。
具体步骤:
- 分割输入文件为M个片,每个片的大小约16-64M
- 一个master,和多个worker,有M个map任务和R个reduce任务将被分配,管理者的一个任务是分配map或者reduce任务给一个空闲的worker
- 被分配了map任务的worker需要做的是读取输入片的内容,分析出k/v对,传递给用户自定义的map函数,产生的中间k/v对缓存在内存中。
- 缓存在内存中的k/v对通过分割函数写入R个区域,本地的缓存对的位置传送给master,然后master把这些位置传送给reduce worker。
- reduce worker通过远程调用来从map worker的磁盘上读取缓存的内容,reduce worker通过排序使得具有相同key的内容聚集在一起。如果中间数据比内存还大,就需要外排序。
- reduce worker迭代排过序的中间数据,对于每一个唯一的key,把key和相关的value传递给reduce函数,reduce函数的输出被添加到最终的输出文件中
- 所有的map和reduce都完成之后,管理者唤醒用户程序,用户程序的MapReduce调用返回到用户代码
Master的数据结构
master首先会存储每个map任务和reduce任务的状态(空闲、进行中、完成)以及工作机器的标识。 master还会存储由map产生的中间文件的区域和大小,然后传给reduce的worker
容错
- worker故障
master会定期ping每个worker,如果一段时间内没有收到响应,master就会将该结点标记为failed。正在进行的map或者reduce更是会重设状态,被调给其他worker。 然而,这些worker已经完成的map任务也会重新设置为idle状态,将会调度给其他的worker,这是因为它们的输出会存在故障机器的本地磁盘上,不过已经完成的reduce任务不需要重新运行,因为它们会存在全局文件系统上。
如果一个map任务在A worker上执行,然后A挂了,被调度给了B worker。所有的在做reduce的worker都会被通知到这个,然后读取对应的中间数据会从B读取。
MapReduce对大规模的worker故障有弹性。
- Master故障
master会定期将内部的数据结构写到checkpoints里,如果master挂了,可以很容易的从最后一个checkpoints开启一个新的副本。
- 失败时的Semantics
即使有故障,也能得到和没故障发生的情况下一样的输出。
依赖于map和reduce任务提交的原子性
本地
带宽是一种相对稀缺的资源,通过GFS存储在cluster的本地磁盘上。大部分输入数据会在本地读取,不消耗网络带宽。
任务粒度
map任务被分为了M个片,reduce任务被分为了R个片,M和R实际上会远高于实际的worker机器,
master将做$O(M+R)$的任务调度,以及保存$O(M*N)$个状态。
备份任务
有时候可能会出现某个任务运行过久导致严重影响整体性能,比如某个worker机器的磁盘坏了导致非常慢的运行,它依然响应服务器的心跳不能认为是failed,但是运行就是非常慢。 MapReduce有一个备份任务的机制,就是当MapReduce即将完成的时候,也就是大多数任务都做完了,那么就会去备份还没完成的任务,只要原始任务或者备份任务的其中一个做完了就可以。
改良拓展、性能表现与实验
上述已经是一个基本的MapReduce的任务了,一些改进拓展、性能表现与实验就不详细说明了,日后可以研究。